6 Months ago I joined Sigma, a User Experienced design agency. I joined as a BA, to support the team and the their clients, designers and developers to evaluate, specify and deliver successful solutions.Movie Passengers (2016)
I had initially thought that I would be part of the development team, having over 5 years experience of delivering software projects, but I’ve found myself working with the UX designers. While design is not what I would have traditionally called my domain, I’ve been surprised at the amount of cross-over my BA skill-set has with that of a UX practitioner.
Both BAs and UX practitioners use analysis, design and research to identify and document business goals and user needs. While their titles might suggest that their roles are focused on opposing areas there is a great amount of overlap.
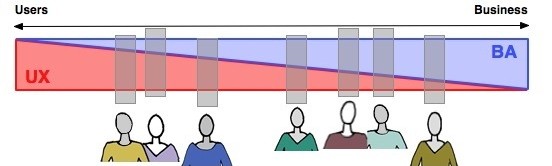
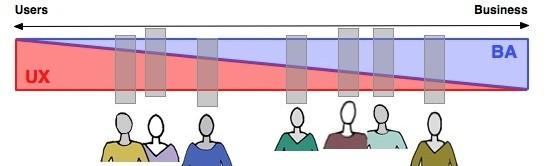
Academics at Berkeley have suggested that the overlap can be viewed on a continuum:
The Berkeley Continuum
So what competencies and skills do a BA and UX practitioner share?
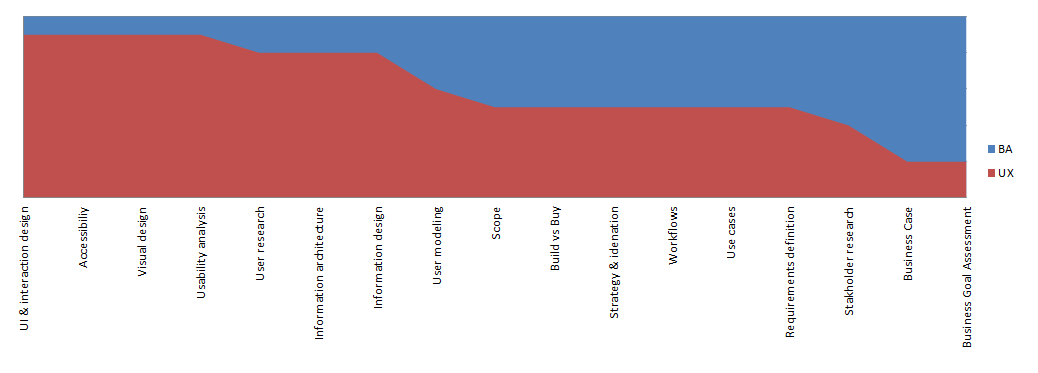
I’ve attempted to map a number of core competencies and skills against the Berkeley Continuum as a way of illustrating what divides and unites the BA/UX roles. It could also be used to identify who is better placed in your team to undertake certain activities. It could also be used to help individuals who wish to transition between the roles, identify which skills they need to develop.
I should note that these are very general classifications of competencies and are not always strictly followed in practice. Just as an example of my own work experience, as a BA I’ve spent a lot of time working in the area of Interaction design (traditionally a UX competency) and yet I have never done a Business case.
But as it’s often said, “It’s not what you’re called, it’s what you do that counts”.
Card sorting is a technique for informing Information Architecture. It allows the architect to collect data on users categorisation preferences and gives them an opportunity to observe users discussing their reasons behind their choices.
Over at Boxes and Arrows Donna Spencer and Todd Warfel describe it as:
A great, reliable, inexpensive method for finding patterns in how users would expect to find content or functionality. [1]
An example
Imagine you’re standing in the supermarket and you’ve been given a list of items to purchase. The list is in no particular order and is completely uncategorised. You read down the list:
Shopping List:
Chicken
Oranges
Sweetcorn
Cotton wool balls
…
In your head you’re already starting to think “Is the Chicken in the meat aisle or the freezer section”, “Do I find the Cotton wool balls with the baby stuff or with the cosmetics”
This is what a user is doing when they come to your site for the first time. They’re trying to find something and they’re looking at the sections on your navigation and trying to work out where to go first. Which section titles best describe what they are looking for.
So how does Card Sorting help us with this? Well we do something similar to standing our users in a supermarket with a shopping list, except this time we ask the to group the items and name the groups in a way that makes sense to them.
Note: The following method is for an observed/moderated experiment. There are a number of great tools available on the web to help you setup remote/unmoderated experiments, however, I find that while these are great for producing a lot of data quickly, you lose the context provided by observing the users as they discuss cards and move them between categories.
Before you start
Picking your cards
I work on the basis that 75 cards will take your users about an hour to sort. So consider how many cards your users will be able to sort effectively in the time available. Also consider which pages to sort. You should strip out any category pages, as these will be replaced by your users newly named groupings. Typically you should be looking at 2nd/3rd level pages.
Preparing your cards
There are 3 things that I’d recommend each of your cards having:
1. A unique ID
This is purely for administrative purposes. It allows you to identify the cards during the analysis phase. Make sure it’s random and doesn’t relate to the section that the page currently lives in (if you’re experimenting with an existing site). Make it small, you don’t want to lead to the users into groupings based on the ID.
2. A page title
If you’re testing an existing site you may be able to pull these straight from the page titles in the metadata. However, if your page titles have been optimised for SEO (or spammed with keywords) you may want to clean these up so that you don’t mislead the user.
Watch out for any pages that may have duplicate names like “FAQs”. Some sites have one of these pages per product or per section, consider renaming it to “Product Name – FAQs”.
3. A short description
Again this may be able to be pulled from your pages metadata. The same consideration applies to SEO optimised descriptions. If the page title is a little ambiguous use the description to supply some context to the page.
Here is an example based on our supermarket scenario:
Free range corn-fed British chickenThis delicious and richly flavoured bird has a characteristically golden colour to the flesh, which comes from its maize based diet. The hens are reared in the same way as our other free range birds.
#1
If you’re any good with a spreadsheet I’d recommend setting up a mail merge to print these. Depending on who you’re asking to take part, their location and the time between the sorts talking place and being able to start the analysis, you may need several sets of cards printing.
Recruiting users
Consider who you’re going to recruit to represent your users. Make sure that your sample is as representative as possible of gender, age, nationality, skill and role/user type.
Card sorts can be done with an individual user but you tend to not get a lot of discussion with users sharing their thought process or opinions. For this reason I’d suggest groups of 2 or 3 users so that there is plenty of discussion, you’ll be able to hear where there is consensus and where there is disagreement.
When recruiting users I would recommend a minimum of 5 groups, as this will give you 5 unique sets of data to analysis. While this is just my opinion it is loosely based on Jakob Nielsen’s Why You Only Need to Test with 5 Users.
If your site or application has a diverse range of users then perhaps consider 3 groups of each user type, or persona if you have created these.
Grab a copy of the analysis spreadsheet
Donna Spencer, whose definition of card sorting I used to open this post, has done a lot of work in the area of card sorting. This includes the production of some fantastic resources and materials to help you with your card sorting.
While the post is 5 years old the resources are regularly updated to ensure that formulas continue to work in the latest versions of excel etc. So for that reason I’d like to point you directly to Donna’s post on the Rosenfeld website.
Running the experiment
After the planning, the preparation of the cards, recruiting your users and scheduling the sorts to take place – running the actual sorts is relatively straight forward. However, there are some things that you can do to make the sorts go more smoothly:
Have a facilitator
If you’ve run any workshops in the past you’ll be more than use to facilitation. You should consider using the same skills to facilitate an experiment. The sorts of things that you should lookout for are as follows:
That everyone in the group is having an equal input
That the group is working as a team and not working against each other
That the group remains on topic
Do your best not to lead a group into making decisions, but you can advise or clarify to some extent if the group are running into real difficulty.
Run through an example
Just as I have given the example of a supermarket in this blog post you should make up 10/15 cards in advance that you can show the group. I like to use items from around the house. This quickly shows that items can be categorised by room (bedroom, lounge, kitchen etc) or by type (electrical, furniture, soft furnishings etc).
Be sure to explain that both are valid ways of categorisation and that the users should go with the approach that they are most comfortable with.
Observing and scribing
As well as having a facilitator in the experiment I would suggest having someone available to observe and scribe. If you have access to an observation lab the scribe could sit in the observation suite taking notes and recording the discussion and actions made by the group. It is not essential that your scribe be hidden away, I have been known to sit in on the experiment, recording, note taking and in some case photographing the groups activities.
If you are unable to get a scribe it as at least worth considering recording the session. Most iPods/iPhones will record through the headphone socket using the headphones straight to mp3 and you’ll be grateful of having something to go back to when you’re writing up your findings.
Spare cards and envelopes
Although this is a relatively low-cost experiment you’ll need to raid the stationary cupboard a few times…
It’s always worthwhile having some blank cards with you. Some users may want to split content or duplicate it into multiple categories, like the cotton wool balls that live in both ‘baby stuff’ and ‘cosmetics’. Allowing your users to duplicate the card by hand and putting it in both categories will act as an aid when it comes to the analysis.
You should also have a number of large envelopes with you. I like to take large A4 envelopes with me and allow the group to write on them and use them as placeholders for their categories. At the end of the experiment you can quickly collect up the cards and store them in the envelope that they are piled on. If you are doing more than 1 sort on the same day ensure you write which sort the cards belong to clearly on the envelopes.
The analysis
Once you’ve populated your spreadsheet with all your categories and cards from your sorts its time to start standardising your categories. When doing this you’re looking for 3 things, in my opinion:
1. The groupings of the cards into categories
Irrespective of the categories name, you want to look out for agreement by users that a set of cards should be categorised together.
2. The names given for the same category
Once you’ve identified that all your users put the cards bread, french stick and bagels into the same category then it’s time to review what they called those groups:
Breads
Baked goods
Bakery
You will have to come up with a naming convention and try to be consistent across all your categories. It may even be wise to consider search term traffic if you are looking to optimise your site for search, when picking a category name.
3. Spotting the dump category
When undertaking your analysis be mindful of the users that were in the groups. Consider their understanding of the content and if they are the target audience for all your content. I sometimes refer to something I have observed in the past as ‘the domain specialists vs. the dump category’.I’ll give you an example, where in a supermarket would you find Quorn (imitation meat mycoprotein) or a USB stick? If you’re a vegetarian or cook for vegetarians there is a good chance you know exactly where to go for the first item. Likewise, if you are into gadgets and are tech-savvy there is a good chance you’ll be able to find a USB stick in a supermarket and you’d know where to put it in a card sort. However, if you are neither a vegetarian or techie then you may simply give up. You may even create a category called ‘Misc’ and dump cards that you don’t know where they fit into it.
More on analysis
There is quite a bit more to the analysis of card sorts, probably enough for another blog post on its own. As I suggested earlier, some of the best resources on ‘using the spreadsheet’ can be found on the Rosenfeld resource site.
Testing your new categories
So once you’re pretty happy that you have your categories, you have the items in them and you have determined a logical hierarchy, it’s time to test your IA. The following 2 methods can help to validate your IA:
Treejack
Treejack is an IA validation tool that allows you to test your IA without visual distractions.
You can create tasks for a user to undertake such as “You want to buy some fresh bread to make bacon sandwiches at the weekend, where would you locate the fresh bread?”.
The tool tracks the users path through the navigation and produces reports on their outcomes.
Task based testing
Once you have Treejack tested your IA it’s time to include it in any prototype that you would build during the design phase of the project. At Sigma we are big advocates or developing prototypes for testing, prior to sites or applications being developed.
Both these approaches will give you insight into how users interact with your categories and the content within them. Based on the results you may want to refine your IA further and re-test.
Conclusion
There are a lot of steps to this post and you may need to refer back to them at different times. The steps to a successful card sort are:
For more on Card Sorting I strongly recommend this book. In it, Donna describes how to plan and run a card sort, then analyse the results and apply the outcomes to your project.
It’s a great addition to the bookshelf and a great reference before, during and after a card sort.
[1] Spencer, Donna & Warfel, Todd. 2004. “Card sorting: a definitive guide.” [online]. Published on 7th April 2004. http://www.boxesandarrows.com
If you’ve been around any software development projects then there is a good chance that you’ll have seen wireframes. Some sketched, maybe some mocked up in prototyping tools or crafted in photoshop. They are a popular tool to help conceptualise page layouts or even go as far as to demonstrate interactions in an application.
The level of detail or interaction that is present in a prototype is often described as fidelity. Fidelity is the degree of closeness to the “depth, breadth and finish of the intended product” (Hakim & Spitzer) [1].
To help explain the difference between low and high fidelity the following definitions are from Usability First:
low-fidelity prototype
a prototype that is sketchy and incomplete, that has some characteristics of the target product but is otherwise simple, usually in order to quickly produce the prototype and test broad concepts. [2]
These are the prototypes that you’d sketch in your notepad when describing the layout of a page or the interaction of an element with a colleague. You may capture them in a meeting with a client as a visual record of what has been discussed, so that you can work them up later into a design concept or higher fidelity prototype.
high-fidelity prototype
a prototype that is quite close to the final product, with lots of detail and functionality. From a user testing point of view, a high-fidelity prototype is close enough to a final product to be able to examine usability questions in detail and make strong conclusions about how behavior will relate to use of the final product. [2]
Unlike the quick sketch in your notebook, a high-fidelity prototype is at the other end of the scale. It’s likely to be rich with interaction, styled graphics and layouts that give the appearence of the finished product.
These are the two extreme end of the scale and in reality you will often be working somewhere between them. Some prototypes will have interactions but not so much visual treatment. Others will be worked up to a high level of design treatment but are just flat images, produced in photoshop with some image regions placed over the navigation to give the impression of a clickable ‘wired-up’ prototype. The reality is that often prototypes are just the vehicle to help us prove a concept or elicit requirements. They are not the end goal, just a means to help you reach it, so we take them as far as we need to go – as far as they remain useful and then we stop and move into code. Your choice about whether you go with a low vs high-fidelity approach is likely to be based on a time/cost/benefit decision, and each project is likely to be different.
There is nothing wrong with low or medium fidelity prototypes. I’ve worked on a number of great projects where this level of prototyping has generated some real rewards for all parties involved. However, more recently I have been working with very high-fidelity prototypes in two new ways. They are:
JAD sessions
Task based user testing
1. JAD Sessions
The purpose of a JAD session is to dramatically reduce the timeframe required to complete a deliverable where consensus is required by getting all of the major decision-makers, stakeholders, and knowledge providers into one place all at the same time.
The real-time production of a prototype during a JAD can help stimulate the discussion, capture decisions and demonstrate ideas and concepts to non-technical stakeholders.
Questions like, “What fields do we want to be capturing during the signup process” are easily answered when a marketing representative is present along with your database administrator. Consensus is reached and the prototype is updated to reflect this detail. The designer gives his input on the layout and one of the developers is able to highlight a constraints of the existing technology stack used. And then you move on to the next decision.
The prototype acts as the living record. The organic deliverable that in the space of 2 or 3 days has grown to encompass all the requirements, decisions and actions.
Task-based User Testing is all about learning how users interact with your application or website in order to access information and complete tasks. Nielsen states that the biggest improvements in user experience come from gathering usability data as early as possible. He estimates that it’s 100 times cheaper to make changes before any code has been written than to wait until after the implementation is complete [3]. With this in mind it’s important to get user feedback and research findings as early in the process as possible, waiting until the site or application is live can be costly and impracticable.
While the prototype is not the finished product it’s important that it is worked up to a very high fidelity so that users are comfortable with its look and feel and aren’t distracted by inconsistent elements or broken interactions. The prototype requires a high level of polish and a set of well crafted scenarios to test and journeys through the prototype.
Working a prototype up to the is degree of fidelity requires time and skill but it’s a worthwhile investment to ensure that you can capture user feedback in the design phase, before any code is written.
Conclusion
Prototyping at any level will give you a great return. Your decisions on how close to make it to the finished product will depend on your budget, your deadline and the influence you are trying to achieve with it.
[1] Farnum, Chris. 2009. “What you should know about prototypes for user testing.” [online]. Published on 29th July 2009. http://www.boxesandarrows.com
[2] “Usability First, Glossary”. Accessed on 11th July 2012. http://www.usabilityfirst.com/
[3] Nielsen, Jakob. 2003. “Paper Prototyping: Getting User Data Before You Code.” Published on 14th April 2003. http://www.useit.com
Recently I wrote about User Stories and how card based software development can help identify ‘clear, brief descriptions of functionality as described from the perspective of a user’.
Today I want to look at how User Stories or ‘Stories’ can impact the user interface (UI) design and user experience (UX) of a software product.
So what is UX?
Don Norman (2007), Nielson Norman Group, describes it as
All aspects of a person’s experience with the system including industrial design graphics, the interface, the physical interaction and the manual.
I like this definition. It goes beyond the traditional Human Computer Interaction (HCI) thinking of physical device design. It goes beyond the point of how a user engages with a mouse and keyboard to get to the site or system and focuses on the software design and how the user interacts with it.
While there are many approaches available to User Experience Designers, Business Analysts and Software Designers, I’m going to be describing my approach to implementing UX in agile projects. I’m going to attempt to directly map these activities to the IIBA’s BABOK V2:
Elicitation
Persona Development
Story Writing
Analysis
Prototyping
Creative design and review
Communication
Managing Stories
Solution Assessment and Validation
Implementation and testing
Elicitation
Persona Development
Early last year I wrote about Users, Roles, and Personas and how they can help you as a BA to understand the users that you are designing systems and solutions for.
Stories are written from the human perspective, e.g. As a user I want to be able to do this or that. This is the shift I mentioned earlier from some of the more traditional “Systems Thinking” where we modelled what the system wanted to do. However, we can take this further by integrating Personas, by making the Persona the voice of the story.Watch Full Movie Online Streaming Online and Download
In other words, if we do a Persona workshop in the early stages of the project, each story that is created should correspond to one or more Personas. Let’s user a Facebook user, Rick, as our example. After modeling Rick and working up a relevant Persona, we can now leverage that in how we create and talk about our stories. For example, we can add a Persona prefix to our story statements:
Rick Says:
As a User
I Want To upload a photo
So That other users can view it
With this short prefix, we’ve both helped to make the story feel real and made a connection to a particular user that will perform this interaction. As we have conversations about this story we can talk about what Rick would want or not want, rather than what some anonymous and disembodied Facebook user.
Story Writing
In a recent post I covered the process of writing user stories using the Card, Conversation, Confirmation format. While I’m not going to cover the entire topic again here I’d like to stress the importance of getting real users to help write stories.
It’s also important to try and separate out design and requirements until you start to prototype and work on design concepts. Try to avoid allowing users to write the sorts of stories where they dictate UI implementation to you. These can often be expressed as “I want to ‘click on a button’ to” or “I want to ‘select from a list’ something”. In my experience a user is trying to help you, but often they are describing a legacy systems implementation of a particular feature and this can distract from why the action is being preformed and focus too much on the how the action will be performed.
Analysis
Prototyping
I could write an entire post on prototyping, and probably should. I am a real advocate of both low fidelity (lo-fi, often used to describe hand drawn or basic static wireframes) and high fidelity (hi-fi, often used to describe interactive prototypes). I am always amazed at how much feedback you can get from users by showing mock-ups and prototypes. As a caveat to this, my last note about not mixing requirements capture and design still stands. Try not to just sketch a quick solution in your notepad and show it to users in workshops. This can sometimes lead to a false setting of expectation and doesn’t allow you to properly test and capture feedback on the design.
Prototypes can perform two key functions:
1. They can be used to give early validation to a solution. Remember, user stories are small chunks of a bigger system. We can get validation feedback that the feature is correct, without having to have every page and feature implemented.
They allow you to observe the user’s interaction with the proposed solution. I often find this activity more valuable then a users verbal feedback. This could take place in the form of formal lab testing scenario or as informal stakeholder reviews.
Creative design and review
In my experience visual treatment is usually applied to a prototype after it has been tested and signed off by the client. However, I know some teams don’t differentiate between the prototyping and creative stages in the process. To these teams the development of the prototype and visual treatment is the same stage, and their prototypes use the brand guidelines and colour pallet to allow for a much richer experience.
This is one of the exciting things about UX. As we move away from traditional HCI, UX is much more about the emotional experience than the physical one. UX is not just about demonstrating functionality ie. “If I click this then…” but far more about the journey that you are talking the user on to make engaging with your feature an enjoyable one.
Visual treatments and concepts can be tested at this stage also. User-centered design (UCD) focuses on analysing and foreseeing how users are likely to use a product, but also in testing the validity of their assumptions in real world tests with actual users. This can be performed in labs or using a range of remote testing solutions.
Like other aspects of agile, this is an iterative process and may take a few rounds of testing, feedback and implementation before the agreed design is agreed and put into production.
Communication
Managing Stories
There are a number of ways to manage stories, from story boards, spreadsheets and project management systems. While I don’t have a personal preference, I do use redmine for the electronic copy of my stories. Like other aspects of documentation on your project the important things to think about are:
Ease of collaboration
Visibility
Traceability
While it’s important to keep good documentation around your stories, these aren’t bound documents that BA’s working on traditional projects will be writing. It is important to think about how you can make them visible to the rest of the team and/or stakeholders. They should living documents, growing organically as more information comes to light.
The benefit of tracking these in a ticketing system like redmine is that you may even be able to offer traceability with the code repository. Other teams may check their stories and tests into SVN to live alongside the code.
Since my last post on the subject I have updated my base redmine user stories template to allow for some additional fields that you may want to capture when performing UX activities.
Solution Assessment and Validation
Implementation and testing
This is one area within the BABOK that I struggle with. While I obviously believe it’s important to validate a solution and test it, I’m not sure that I agree that this is a formal activity that happens at the end of the development life cycle. I think that the BABOK may be referring to a degree of formal signoff or UAT that takes place, however, on agile project my experience is that this happens on a much more regular occurrence.
Testing and validation of a solution can identify issues that can often be quickly and inexpensively corrected during the prototyping and design stages.
Conclusion
As Business Analysts we need to consider the use of such practices in our toolbox to help us communicate and demonstrate solutions to our clients or business teams. At the same time they can be used to collect rich feedback on a project before a single line of code is written.
On my last project we had a play with running a Kanban board. I’ve used Scrum on a number of occasions and am quite comfortable with writing User Stories and Tracking Estimates and Velocity but Kanban was something quite new.
Kanban is a JIT system that has its roots in the Toyota production system circa. 1940/50. It’s based on a simple queuing system that is intended to reduce the overall load of individual resources (designers, developers, testers, etc) by ensuring that packages are supplied to each resource just-in-time, preventing bottlenecks and/or too much slack in the process.
Kanban is a methodology for managing the flow of work to allow for evolutionary change.
There are 4 key aspects to implementing Kanban, they are:
Visualise the work
Limit work in progress (WIP)
Focus on flow
Continually Improve
Let’s look at those in a bit more details.
Visualise Workflow
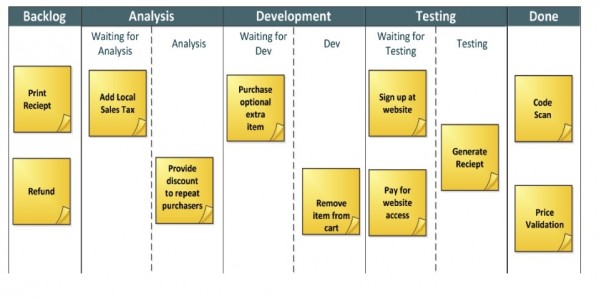
Visualising your workflow involves getting the tasks required for a project or package of work up on a board, as this the interpretation of Kanban (カンバン?), literally meaning “signboard” or “billboard”. There are a number of electronic systems for this, but I find that getting a board up in a space that your team can get around adds great value and a great opportunity for collaboration amongst the team.
The board is divided into swim-lanes and cards or tasks move from left to right until completed. This gives the team, not just the project manager, visibility on where bottlenecks are building on the board.
Different teams will pick different names for their swim lanes but I think the above is a good starting point for lane names.
Limit work in progress (WIP)
Limiting work in progress is the process of determining the maximum number of cards that can be worked on in any swim-lane. In the example shown in Figure 1, we can assume there is a development limit of 2. That is to say that the total number of cards that can be across both Waiting for Dev and Dev can not exceed 2. If we look at testing and assume that the testers have a lane limit of 3 then the following is true:
Dev can not put anything else in to test until “Generate Receipt” is Done.
Dev can not ‘pull’ anything else from Analysis until they move at least one card into Testing.
As soon as a task is completed in testing a vacuum is created and test can pull from development, development can pull from analysis and analysis can pull from the backlog.
Once you start to reduce WIP you start a continuous improvement cycle within the process. This allows you to make better decisions on your resourcing profile on the project.
Focus on flow
Flow can be measured using CFDs or Cumulative Flow Diagrams. These diagrams can be really useful when attempting to analyse flow through the board and identifying areas for improvement.
The following diagram shows a simple but accurate example of how a CFD can be used to show the amount of tasks in each lane over the duration of the project. we can see that at the beginning of the project the backlog was large (to-do), the in progress work was very small and there was no work completed. On days 6, 11, 20 and 24 deployments were made pushing work from in progress to done.
The CFD can be used as a tool to show the effects of any changes that you make to the team or your WIP policies throughout the duration of the project. Track if individual changes have a positive or negative effect on the flow through the board. At this stage you should be looking to optimise for more predictable flow.
The following may help for produce improvements:
Investing in CI tools to help your team deploy more regularly
Implementing WIP limits and Pull Conditions
Training developers to write tests for their code. This may improve quality and reduce the amount of time code sits in test
Increase resources in one of your skill areas
Every team understand its own pressures and resource/investment constraints. However, a CFD will help you optimise your flow within those constraints to produce a predictable flow of delivery.
Conclusion
Kanban is a very powerful tool for helping a team understand where bottlenecks are in production and gives tools to help track the effects changes to the pipeline may effect that bottleneck. Some of the best advice I had from a member of my team who had a lot of experience with Kanban was:
Last week I was thinking about how to capture and analyse business rules and data requirements for a current project. I’ve worked on a number of projects where the focus can often be on either rules or data, however focusing on one while leaving the other out can cause issues further on in the project life cycle. I’ve learnt this on previous Business Intelligence/Data Warehousing projects where over analysis of the data can lead analysts to start to ask more questions of the data then the end-users or owners ever wanted to ask, while key rules are not enforced.
A declaration of policy or conditions that must be satisfied…. In order to define, stream or enable our system or process behaviour. (Gottesdiener 2005)
Mary discusses 4 types of rules that can aid a BA in categorising rules and their corresponding data dependencies. These 4 rules are:
Term Rules
Fact Rules
Constraint Rules
Derived or Calculated Rules
I am listing them below more for my own reference benefit, but hopefully others will find them useful.
Term Rules
Defining nouns such as “Customer” or “Gift Card” is important. This task is not just for your glossary but for giving context to your system or process. We’re able to identify actors (Customer) from terms based rules and this helps us define the scope or boundary of the work to be undertaken.
Fact Rules
Fact rules are a two way relationship between terms rules. For example:
A purchase is paid for by a gift card
A gift card pays for purchases
These can be extended to use cardinalities
A purchase may be paid for by one or more gift cards
A gift card may be paid for by one or more purchases
As we identify fact rules we can determine data attributes. For example:
A customer has an address. An address is made up of address lines, city and location.
Defining these data types allows us to define the scope of the rule. For example we don’t want a second address line.
Constraint Rules
Constrain rules can be used to constrain the action of a rule. In this example an expiration date is added to the gift card.
gift card expiration date must be equal to or greater than purchase date.
Derived or Calculated Rule
A calculated rule allows us to derive new attributes from existing ones. For example:
A gift card date is calculated from the date of activation plus 365 days.
Gottesdiener, Ellen, The Software Requirements Memory Jogger: A Pocket Guide to Help Software and Business Teams Develop and Manage Requirements. Goal/QPC, 2005
Last week I had the pleasure of attending ThoughtWorks Live 2011 in London’s St Martin’s Lane hotel. The conference, entitled Continuous Delivery: Push the button, was a showcase of ThoughtWorks thinking on how to become truly agile through the implementation of Continuous Delivery and Continuous Deployment.
Among the speakers were heavyweights such as Martin Fowler, ThoughtWorks Chief Scientist & Roy Singham, ThoughtWorks Founder & Chairman – positioning ThoughtWorks as not only global experts but as global educators, both practically and aspirationally.
Riding Paradox
"Paradox" by Michael Bergt
A real favourite for me was a presentation given by ThoughtWorks Studio’s Managing Director, Cyndi Mitchell on Adaptive Leadership: Accelerating enterprise agility, based on Jim Highsmith’s whitepaper of the same name. In the presentation Cyndi discussed a number of challenges that leaders face in being adaptive. The real eureka moment for me, in both the presentation and the whitepaper, was the concept of Riding Paradox. We were encouraged to be ‘And’ rather than ‘Or’ leaders, inclusive of elements from multiple methodologies that can add value and work together for the benefit of the project. No one methodology has it 100% right and we should look to take aspects of different practices and thinking and incorporate them more. A quote from Rotman summed it up well “Integrative Thinking is the ability to constructively face the tensions of opposing models, and instead of choosing one at the expense of the other, generating a creative resolution of the tension in the form of a new model that contains elements of the both models, but is superior to each“.
Highsmith discusses in his whitepaper “The paradox horse seems always to be going in opposite directions at the same time. Furthermore, the leader is exposed, drawn by the traditional norms of many organizations in which it’s OK to be wrong, but not OK to be uncertain“.
As a Business Analyst I often find myself in a similar position, for two reasons. Firstly, due to the nature of my role I report into my Managing Director for the purpose of sales targets and planning, while reporting into my Technical Director for the purpose of scoping and quality assurance. It can often feel like attempting to serve two masters, serving two areas of the business who sometimes have opposing expectations.
Secondly, clients can sometimes be prescriptive about the methodology that their software project should use. This is rarely based on thoughtful consideration of stakeholder needs, rather that the client has heard a buzz word or has used that methodology on a previous project and feels safe with it. As an example, I have had clients come to me and say “We want to use Prince2”, for no other reason then a third-party advisor has suggested it would ‘be best’. This leads to lengthy planning and scoping phases of work up-front which the client is happy with. However, once the project moves into production the development team opt to take an agile approach to the job, breaking down my long specification into chapters – renaming them iterations and delivering little and often.Watch Full Movie Online Streaming Online and Download
At the same conference one of the speakers, Dave West from Forrester, coined the phrase “Water-Scrum-Fall” that perfectly describes this idea that scoping happens, the development team run off with an agile approach and then the final mile of the project reverts back to a very formalised sign-off process.
I’m excited by what I’ve heard at the conference and challenged to implement changes in my working practice. Lets hope I can attempt to ride paradox without falling off!
This week I have been revisiting the topic of Stakeholder Interviews, in the hope to refresh my own thoughts on the subject. I’ve found some great resources that I would like to share along with a number of hints and tips that I have from my own experience of undertaking Stakeholder Interviews. I should note that this post is not intended to be a definitive list of potential questions, more a guide to those who wish to understand how to undertake Stakeholder Interviews.
Firstly, what is a Stakeholder Interview? Well – I couldn’t find a book definition to reference, so I have made one up:
An interview between a Business Analyst/Project Manager and pre-identified stakeholders of an organisation or department, for the purpose of understanding a current system and/or eliciting requirements for a new system.
Like many interviews that you will have taken part in, either in seeking employment or helping in market research, they follow what is known as a structured interview style.
Bryman & Bell (2003) describe the purpose of the structured business research interview as being “for the interviewer to elicit from the interviewee or respondent, as he or she is frequently called in survey research, all manner of information: interviewees’ own behavior or that of others, attitudes, norms, beliefs and values.”
So now that we know what a Stakeholder Interview is, how do we undertake one? Thanks to Brad Botz over at BA Mastery, I came across a great podcast that he put together on the same topic. Brad suggests breaking down your questions in the following way:
Function
– How do you use this software? What are some examples of what you do regularly? Which actions do you perform the most?
Frequency
– How often do you perform these tasks?
Preferences
– What do you like best about the software?
Problems
– What problems do you run in to on a regular basis?
Expertise
– What are the tips and tricks that you have learnt? Are there any workarounds that you have discovered to make the tasks easier?
Miscellaneous
– Have I missed anything? Is there anything that you would like to show me?
It is important when to stay on topic with this last set of questions. Try not to allow the stakeholder to deviate from the original purpose of the interview and remain positive about the system, even if their own concerns or experiences are negative. It’s also to remember to let the stakeholder follow the course that they wish to take throughout the interview. While it is appropriate for the interviewer to help guide the respondent, encouraging them down a particular route is not appropriate and should be avoided where possible.
In Summary
Advantages:
If you build a rapport you are going to get much more acceptance of the project, not just through the interview but throughout the life cycle of the project
Its easy to conduct interviews – easy to extend them if they overrun and easy to record their findings
Disadvantage
It can be difficult to obtain consensus if there are many stakeholder
Follow up questions are heavily reliant on the interviewers experience of the interview process and their understanding of the domain they are working in
Recently, I have been doing some work with User Stories. As a result the developers and I have started to estimate user stories using story points. This is a good way to allow a team of developers to collaboratively estimate the complexity of a piece of functionality and how long it will take to implement.
The question was asked about how we make our progress visible to internal and external stakeholders of the project. Unlike a traditional waterfall project there is no gantt chart or detailed project plan, only a series of iterations and some expected deliverables for each iteration. This lead us to think about how many story points we were expecting to complete in any single iteration.
Many of the projects that I have worked on in the past use Burndown Charts, but most of them were produced out of a project management tool. I decided to take the user stories that I had from the current project and have a go at producing my own Burndown Charts.
Using Google Docs I was able to take data from the user stories, broken down into the 5 iterations, or sprints as some prefer, and produce a burndown chart.
Traditional Burndown Chart
However, when I looked at it I couldn’t help but think that it looked too good. Like the project had been too easy. I went over my notes and I was reminded of two things that happened during the project:
The teams estimates changed
Scope creep set in
What that actually meant was that while the project looked like it had gone really quickly and that we had over estimated the user stories in each iteration, there had been some changes mid-project that we had negotiated and these had effected the overall number of story points in the project. To better show this I have produced a second chart that I think helps stakeholders see the movement in scope in relation to the burndown.
Burndown (including scope creep)
The addition of the ‘scope’ line shows the burn down in a slightly different light.
At the end of iteration 1 (i1) the developers are behind of where they should be. Being an iteration in and being able to rework their estimations they deem some tasks to be more effort and increase their estimations to match. This saw an increase of 5 story points, 2.6% of the project.
At the end of iteration 2 (i2) the client team dropped a piece of functionality. We were able to cater for this change and thus removed 18 story points, 9.5% of the total project.
The rest of the project continues on its projected line but had there not been an additional line to show change the client team could have easily misunderstood why the project was in its current state.
I don’t know how people feel about using such charts and if hacking them to show more information is allowed. I believe strongly in giving clients as much useful information and feedback as is possible. It is important that a client team see a strong correlation between scope creep and effort. If the scope of a project is increased a project will, in most scenarios, take longer. However, if a scope is decreased then often there is time savings.
That last point about time is one thing that I should extend on. We struggled to take the conceptual theory of a story point, determine a velocity and then convert that to developer days. In the end we settled with estimating in developer hours, so 1 story point = 1 dev hour. This seems like a bit of a cheat and not as pure as intended, if anyone has suggestions on how to improved project estimations I’d love to hear from you.
The ability to understand a user and their role in a software system is not a new thing to many. We have all interacted with applications and software where there is, at minimum, a normal user and an administrator. Users can’t do all the things an administrator can do and an administrator can do all the things a normal user can do – plus some additional things.
However, when we look at systems in this way all we are really modelling is permissions. Who has permission to perform a task? Who is allowed to perform an action? If someone does something wrong who will moderate this? These are all valid questions about the systems and it’s intended Access Control List (ACL), but captures nothing about the individuals that will be using the system, what their goals are and what things we can do with the interface that will improve performance for the users.
I found myself in this position on a recent project and something I read caused me to rethink my approach. This is what I read:
User roles do not resemble real people nor are they intended to; roles are spartan abstractions narrowly focused on those aspects of the relationship most likely to be relevant to presentation and interaction design. Compared to personas, user roles are a more technical and formally structured model.
By contrast, personas are figurative models rather than abstract models, that is, they are constructed to resemble real users, even down to photos, background information, and personal history. Verisimilitude most likely contributes to the popularity of personas. They sound like people you could know, and over the course of a project can take on a reality that encourages empathy and facilitates thinking from the user perspective. What is more, many people find that the creative process of constructing personas to be engaging and energizing. Personas are fun. (Constantine 2005)
The suggestion here was that when modelling users for a system it wasn’t a case of picking one or the other, role models or personas, but that really the two needed to be carried out together in order to get the fullest picture of how a user would use the system and what they wanted to achieve from the system – not just what they would have permission to do.
I decided that it was time to put this into practice, to give it a go. Was I going to add the persona modelling to my toolkit or not? The system I was working on (and still am currently) is for managing learners in a learner centre. The scenario I am going to use as my example is quite simple: Learners attend the centre in the morning and are greeted and registered by a ‘learner administrator’. The learners then commence on a piece of learning and are assessed by a ‘tutor’.
In this scenario I identified two users a learner administrator and a tutor, the learner was not interacting directly with the system. However, due to resourcing issues at the centres it was important that learner administrators and tutors had the ability to perform the same actions. In essence the two users share one role.
So under the role based model this is fine, nice and simple. I don’t really need to create two user types I can just create one and add a label that just identifies their job title, in case I ever need to reference it somewhere. However, I’d decided to add personas and see if anything changed. Here are my personas:Watch Full Movie Online Streaming Online and Download
Learner Administrator
Sarah is a single mum in her early twenties. Her day consists of checking students in, chasing the ones that haven’t turned up and ensuring that the correct reports are run so that the centre can claim its allocated funding for the learners they have had through the door. Between admin tasks Sarah uses Facebook to see what others are up to and uses an IM client to chat to her boyfriend. She’s a confident computer user who finds the system easy to navigate.
Tutor
Phillipa is an ex-school teacher. She works as a tutor part-time more to keep her busy rather than because she is dependent on the income. Phillipa has older children who are no longer at home and her husband is a consultant surgeon. Her day-to-day tasks are the assessing of learners, recording their outcomes and helping them to move on to the next piece of learning. Phillipa is focused on the learner and finds the need to record everything on an online system a chore. She only uses about 25% of all the systems functionality but the areas that she does use are used relatively. Phillipa doesn’t mind using a computer for her tasks but likes to have peoples on hand to check with and ask questions when needed.
From this it became very obvious that my two users with the same permissions role were going to be using the system for very different purposes. I had been able to identify this early, rather than waiting for User Acceptance Testing (UAT) and I was able to do something about the design of the system and its interface.
The system has not been fully implemented yet but one suggestion that has come out of this was a configurable dashboard. The dashboard is made up of a number of blocks and pods that either display content or a forms and filters into other areas of the system. The layout of this dashboard would be dictated by the priority of certain day-to-day jobs, allowing for learner administrators and tutors to rearrange these pods to suite their needs. Also, based on the understanding that the tutors were generally older, less computer savvy users I opted to prioritise the default dashboard around their needs so that they would need to do less configuring, allowing the more confident learner administrators to customise their dashboards heavily.
So what did I learn from this exercise?
I learnt that an ACL role model isn’t always enough
Roles need context. Personas allow us to add context
You can create an interface that is different for two users but only charge them for one.











")

 Learner Administrator
Learner Administrator Tutor
Tutor The system has not been fully implemented yet but one suggestion that has come out of this was a configurable dashboard. The dashboard is made up of a number of blocks and pods that either display content or a forms and filters into other areas of the system. The layout of this dashboard would be dictated by the priority of certain day-to-day jobs, allowing for learner administrators and tutors to rearrange these pods to suite their needs. Also, based on the understanding that the tutors were generally older, less computer savvy users I opted to prioritise the default dashboard around their needs so that they would need to do less configuring, allowing the more confident learner administrators to customise their dashboards heavily.
The system has not been fully implemented yet but one suggestion that has come out of this was a configurable dashboard. The dashboard is made up of a number of blocks and pods that either display content or a forms and filters into other areas of the system. The layout of this dashboard would be dictated by the priority of certain day-to-day jobs, allowing for learner administrators and tutors to rearrange these pods to suite their needs. Also, based on the understanding that the tutors were generally older, less computer savvy users I opted to prioritise the default dashboard around their needs so that they would need to do less configuring, allowing the more confident learner administrators to customise their dashboards heavily.